Terraform gained popularity with the rise in adoption of cloud, many teams that operate on cloud need a way to quickly and securely launch, update and destroy infra. Terraform manages external resources with providers notably major cloud providers AWS/Azure/GCP. Terraform uses declarative configuration to describe the desired final state. The Infrastructure as code can be written as modules ,thus enabling reusability and maintainability.
In this article, we will try to create a simple job, you may want to clone the repo to follow.
Prerequisites:
- AWS account and some knowledge about AWS Services and setup
- Terraform CLI VS Code
- Install on Mac OS using below commands, for other OS, use this link
brew tap hashicorp/tap
brew install hashicorp/tap/terraformAs part of any data engineering project, you may be tasked with ETL ( extract, transform, load) tasks that deal with reading data from a source. One of the many tools we have available is AWS Glue for server less ETL.
we will look at simple Python test job that we can create on Glue using Terraform and the framework can be extended for bigger ETL tasks. All Glue jobs need the script to be made available on S3. So we need to create a bucket on S3 and upload our test scripts before the actual glue job runs. We usually run CI/CD Jenkins pipeline to upload all your scripts to S3 folders from your GIT, that’s a discussion for another day.
Step #1
~/.aws/credentials
[default]
aws_access_key_id=AKIAIOSFODNN7EXAMPLE
aws_secret_access_key=wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY~/.aws/config
[default]
region=us-west-2
output=jsonNow terraform declarative script can be defined to start off with these settings.
provider "aws" {
shared_config_files = ["/Users/tf_user/.aws/conf"]
shared_credentials_files = ["/Users/tf_user/.aws/creds"]
}if it’s easier we can directly define aws_access_key_id and aws_secret_access_key part of the terraform script, but we are discouraged to so, as it will provide everyone access to the credentials, always important to declare them part of files and provide the path to Terraform to pick it.
Step #2
We need a bucket that holds all the glue scripts together and we let terraform build it for us using the below setting.
resource "aws_s3_bucket" "glue" {
bucket = "avi.ravipati.gluescripts"
}We also need to setup cloud watch logs [Glue writes output/error] to capture any logs out of our Glue jobs, which is defined as part of AWS documentation
Step #3
We need to define IAM role and attach a policy for our glue job to communicate with other AWS resources.
Here, we have Glue job assuming a role, for which we have attached a policy that has full access to S3.
resource "aws_iam_role" "terraform_glue_role" {
name = "terraform_glue_role"
# Terraform's "jsonencode" function converts a
# Terraform expression result to valid JSON syntax.
assume_role_policy = jsonencode({
Version = "2012-10-17"
Statement = [
{
Effect = "Allow"
Principal: {
Service: "glue.amazonaws.com"
},
Action: "sts:AssumeRole"
},
]
})
}
resource "aws_iam_role_policy" "terraform_glue_role_policy" {
name = "terraform_glue_role_policy"
role = aws_iam_role.terraform_glue_role.id
# Terraform's "jsonencode" function converts a
# Terraform expression result to valid JSON syntax.
policy = jsonencode({
Version = "2012-10-17"
Statement = [
{
Action: [
"logs:DeleteDataProtectionPolicy",
"logs:DeleteSubscriptionFilter",
"logs:DeleteLogStream",
"logs:CreateExportTask",
"logs:CreateLogStream",
"logs:DeleteMetricFilter",
"S3:*",
"logs:CancelExportTask",
"logs:DeleteRetentionPolicy",
"logs:DeleteLogDelivery",
"logs:AssociateKmsKey",
"logs:PutDestination",
"logs:DisassociateKmsKey",
"logs:PutDataProtectionPolicy",
"logs:DeleteLogGroup",
"logs:PutDestinationPolicy",
"logs:DeleteQueryDefinition",
"logs:PutQueryDefinition",
"logs:DeleteDestination",
"logs:PutLogEvents",
"logs:CreateLogGroup",
"logs:Link",
"logs:PutMetricFilter",
"logs:CreateLogDelivery",
"logs:UpdateLogDelivery",
"logs:PutSubscriptionFilter",
"logs:PutRetentionPolicy"
],
"Resource": [
"*"
]
},
]
})
}Step #4
Now onto the last step to defining our glue job, we can find the syntax needed by visiting Terraform official documentation. The easiest way is to go to the documentation page and type the resource you want and it will show different functionalities we can do and pretty much show examples on how to define. Our glue job will start running our custom script using IAM role that we have created in Step #3.
Before we run the job, we need to manually upload our python script into S3 bucket we defined earlier.
resource "aws_glue_job" "test_py_job" {
name = "test_py_job"
max_capacity = 0.0625
#max_retries = 2
role_arn = aws_iam_role.terraform_glue_role.arn
command {
name = "pythonshell"
script_location = "S3://${aws_s3_bucket.glue.bucket}/hello_world.py"
python_version = 3
}
}Final Step to create infrastructure
1.terraform init #Initiates and downloads config files
2.terraform plan #shows the proposed changes for review
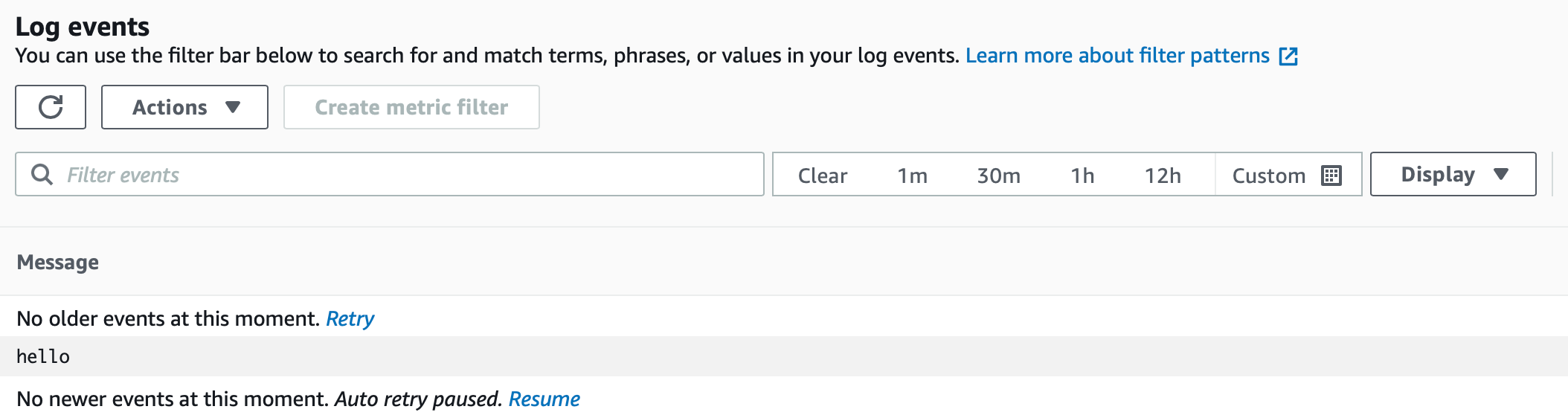
3.terraform apply #Deploys the infrastructure Now you should see a glue job created, you may run it and see the output logs.
Conclusion
we can modify the script to run anything including connecting to other AWS services using Boto3 library, that’s a topic of discussion for another day.
Have fun playing around with it.
I was wondering if anyone has setup GPT3 with Terraform
Happy learning !!